AI agents can analyze healthcare data at unprecedented speed—but they're only as effective as the data behind them. Learn how health systems are combining AI-ready data infrastructure with agentic AI to reduce referral leakage, uncover growth opportunities, and accelerate strategic decision-making.

Chief Analytics Officer

Director, Marketing
The key takeaway from this webinar is that deploying AI agents for healthcare strategy analysis is not primarily an AI problem — it is a data problem. Before any agentic system can return a trustworthy answer, the underlying data must be structured, normalized, and enriched in ways that most health systems have not yet accomplished.
This session, presented by Kythera's Chief Analytics Officer, addresses the foundational requirements for running AI agents on healthcare data and demonstrates a working multi-agent system applied to surgical market share and referral analysis.
In summary, the wrong-at-scale problem occurs because AI agents surface whatever is in the data and present it as fact. If the underlying data is incomplete, mismatched, or carries structural artifacts (such as a claims data lag that makes procedure volume appear to drop when it has not), the agent will return a confident but incorrect answer. The agent itself does not know the data is flawed. This is the core risk: scale amplifies errors rather than catching them.
Before an AI agent can answer a question like "what is my market share for orthopedic procedures in the Atlanta metro?" it must have access to data that has been prepared across several dimensions. Internal healthcare data — revenue cycle, EHR, claims — is designed for operational use, not strategic analysis. It must be transformed into a patient-event model that makes referral patterns, episodes of care, and market dynamics queryable. Third-party claims data must be linked to internal data in a HIPAA-compliant way, and that linkage must account for the many ways the same patient or facility appears differently across data sources. According to Gartner, 60% of AI projects will be abandoned due to unsupported AI-ready data — a figure that reflects how common this preparation gap is.
The session demonstrates that production-grade AI analysis for healthcare strategy requires a team of specialized agents, not a single general-purpose model. The architecture shown includes a team lead agent that interprets user questions and routes sub-tasks, a practitioner directory analyst, a facility directory analyst, a patient events analyst, and a coverage advisor. The coverage advisor is particularly important: it proactively flags data sufficiency limitations before they become errors in the final output. In the live example, it correctly identified that a sharp apparent decline in procedure volume was caused by a Medicare data lag in the underlying claims, not an actual market change.
Two use cases are demonstrated using Kythera's patient events dataset, which covers just under 300 million patients over eight years. The first is a market share analysis by service line and geography. The second is a referral opportunity analysis that identifies physicians who demonstrate distributed referral patterns — meaning they are not exclusively affiliated with a competing system — and ranks them as outreach targets. Both analyses are produced by the agent team in 7 to 10 minutes from a plain-language question.
The Central Problem: Garbage In, Confident Out
AI agents do not know when the data they are querying is wrong. Unlike a human analyst who might question an anomalous result, an agent will surface what is in the data and present it as fact. This means data quality errors do not produce obviously bad outputs — they produce plausible-looking outputs that are wrong. In a strategy context, where decisions about capital allocation, service line expansion, and physician recruitment follow from analysis, confident-but-wrong is worse than no answer.
The webinar frames this as the "wrong at scale" problem: as AI agents are used for more decisions and by more people, the error-multiplying effect of bad data compounds. The solution is not better AI — it is better data preparation.
The session opens with a definition that is useful for non-technical audiences. Large language models like ChatGPT and Claude are general-purpose chat interfaces trained on broad internet data. They can interpret questions and generate answers from that general knowledge.
Agents differ in one specific way: they have been given tools and connections to external systems that allow them to take action, not just generate text. An agent can query a database, retrieve records, and return a data-driven answer — or it can modify records in a CRM, an EHR, or another system. The distinction matters because running an agent on internal healthcare data requires both a connection to that data and a governance architecture that ensures patient data does not leave the organization's infrastructure.
The webinar addresses a specific question about using tools like Claude Code to connect a general-purpose model to internal data. The answer: technically possible, but the architecture must be designed carefully. Without proper setup, queries against internal data can round-trip through external foundation model servers, which creates a HIPAA exposure. The solution is to run the model within the health system's own Databricks environment, not against an externally hosted API.
For an AI agent to return reliable answers from healthcare data, the following preparation work must be in place:
For data analysis tasks, the session argues that a single general-purpose agent produces worse results than a team of specialized agents. The reason is reliability: the more narrowly scoped an agent's responsibility, the more precisely it can be tuned and tested. An agent that knows only the practitioner directory will not make mistakes about practitioner data. An agent that knows only the patient events dataset will not mix up event types.
The first use case demonstrates a common strategy question: what is the market share of health systems in a given geography and service line?
The team lead agent first calls the facility directory analyst to resolve the hospital systems in the Atlanta market. It returns a list that includes the system’s hospitals and four primary competitors. The team lead then asks the user clarifying questions: core metro or broader geography? What time period? Which service line? The user specifies core Atlanta metro, the last two years, and orthopedics.
The events analyst then queries surgical procedure volume by facility and system, returning year-over-year market share figures. The coverage advisor flags that volume data after July 2025 reflects a Medicare claims lag and that figures through June are more representative of competitive position. The final report includes an executive summary, market share rankings, year-over-year trend data, and facility-level benchmarking. The total time from question to report: 7 to 10 minutes.
The second use case applies the same agent team to a business development question: which physicians in the market represent the best opportunity to increase referrals?
The user asks for physicians who send fewer than 70% of their orthopedic patients to any single surgery practice — meaning they are "splitters" who are not exclusively affiliated with a competitor. The team lead routes this to the events analyst, which queries referral pattern data across physicians with at least 100 orthopedic patients in the period.
The final report identifies 177 physicians matching the criteria in the Atlanta area. It ranks the top 20 by volume-to-concentration ratio, provides key insights on specific high-priority targets (noting affiliation status and referral distribution), breaks down the geography of target physicians, and provides strategic recommendations for immediate outreach — including suggested talking points tied to the target system's specific capabilities.
The analysis is based on actual claims and referral data, not benchmarks or averages. Every physician identified, every volume figure cited, and every referral pattern described comes from the underlying linked dataset.
# Webinar Transcript
**Title:** Wrong at Scale: Strategy AI Agents Are Only as Good as the Data Behind Them
**Host:** Kythera Labs
**Speakers:**
* **Caitlin Ryan**, Director of Marketing, Kythera Labs
* **Ryan Lerch**, Chief Analytics Officer, Kythera Labs
\---
### Introduction
**Caitlin Ryan:** Hi, everyone. Welcome to "Wrong at Scale: Strategy AI Agents Are Only as Good as the Data Behind Them." I'm Caitlin Ryan, Director of Marketing here at Kythera Labs, and I'm joined today by Ryan Lerch, our Chief Analytics Officer.
A few housekeeping items. We have reserved time at the end of the presentation for Q\&A, so feel free to submit your questions as we go. If we don't get to your questions, we will definitely reach out and follow up with you. And we'll also be recording today's session, so we'll send you that link once it's processed so you can share with your colleagues.
All right. We only have about 30 minutes and a lot to cover. Ryan, you want to get started?
**Ryan Lerch:** Sure thing. Yeah. Thank you, Caitlin. I'm going to take over here, and I am going to share my screen. Okay. Hopefully, that's coming through for everybody.
\---
### The State of AI and Agentic Applications
**Ryan Lerch:** So yeah, we're going to talk today about AI, particularly about AI agents. Everybody is talking about this. You can't read anything on the internet or go to a conference and not hear about AI in literally every single session. I just came from a few and honestly, it seemed like it was a requirement for anybody that was speaking or interviewing to talk about AI.
And one of the things that I was noticing was that there was some general level of confusion still. I think the market is moving forward, and people are starting to get their arms around what AI might be able to do for us and how we might be implementing it in our organizations. But I think that there is such a rapid pace of change that sometimes it's hard to keep up and understand really where does this fit within your organization, for example, as a health system or a hospital. So we're going to talk a bit about that today, just to try to draw some boundaries around the definitions and hopefully bring some clarity to what really might be possible currently and in the near future.
So the big question here in terms of the use of agentic AI in particular, there's a myriad of different use cases, right? And I think at this point, everybody has had a chance to use AI in some form or fashion. Some of you are probably using it every single day, in your day-to-day job, whether it's ChatGPT or Claude or one of the others.
The use case that we're going to talk about today is really about bringing that capability in-house onto data that lives within your own system, which has been a really big challenge, particularly in regulated industries like banking and healthcare. So how do we get these things to look at our own data, right? Can we ask an AI agent that's looking at our data a question and get an answer back? But more importantly, we want to be able to ensure that it's accurate, right? It's complete, and that it's not something that we have to wait a ton of time for. So with that in mind as motivation, we're going to dive right in.
\---
### Chatbots vs. AI Agents
**Ryan Lerch:** So first, just a little bit of definitions here. I mentioned ChatGPT and Claude in the beginning, right? These are chat interfaces. They're foundation models, trained on basically the entire internet. So their knowledge is very general, and can be used for a whole bunch of things. You've all seen amazing use cases. Those have the ability to understand what you're asking them, interpret it, and then generate an answer that's built upon mostly their general knowledge.
Chatbots differ in a significant way from agents, and I would say that the main way that they differ is that an agent is not only able to, say, answer a question, but it's been provided with tools and skills that enable it to actually interact with external systems, right? So, whether it's asking your agent to change something for you in Salesforce or asking an agent to change something in an EHR database, for example. That's the difference. They have the ability to effect some sort of change apart from just giving you an answer.
Now, when we think about this in terms of how do we get an AI agent to look into our data to answer questions that are maybe motivated by the strategy department or marketing department, and really do some deep data analysis, that... poses some unique challenges because we have to make sure that the data first is in a state of readiness for that AI agent to even begin working on.
*(Apologies, folks, I keep pressing the wrong button. There we go.)*
One of the big challenges with an AI agent—I love this movie, hopefully some of you guys are familiar with this—but just like Ron, these AI agents will surface whatever's in the data and answer your question as fact because, hey, that's what the data says, right? And so if we are not really careful with what we're putting into or giving the AI agent access to, we're going to get an awful lot of mess out the other end.
\---
### Infrastructure Challenges and the Data Layer
**Ryan Lerch:** So that lays out the challenges. And so for you that are trying to determine how you are going to get some of this type of capability within your own organization, you've probably identified at least a few of these issues that lay before you. There's a lot of infrastructure and foundational work that you have to do in order to begin using these things on your internal data.
First, all the data work itself, right? Assembling that data. You guys are all familiar with the multitude of data sources in your own internal systems. They have inconsistent formats and schemas, et cetera. There's third-party data; it obviously doesn't line up with your internal data natively.
Governance and security are huge issues, right? How do we enable this in a HIPAA-compliant way, and consumer protection law compliant way? And then given that we've got all that figured out and the infrastructure for that in place, I still have the question of the AI, right? What are these things? How do I get them integrated into the system? And then, of course, there's the fine-tuning and validating that so that it's answering questions that are relevant to your specific organization and doing so accurately.
All of this means when you look at some of the organizations out there that are helping the tech industry, like Gartner, they predict that 60% of all the AI projects are going to be abandoned because of unsupported AI-ready data. So a huge hurdle to overcome.
\---
### How it Looks in Practice: Multi-Agent Systems
**Ryan Lerch:** So how does this look in practice, right? On top of the raw healthcare data—this is stuff that you guys are all familiar with, that we're drawing it as a big gray box here—but this is your revenue cycle management, right? This is claims, external third-party claims data, for example. This is EHR data. And all of this data exists in your organization, but its purpose is mostly operational, right? This data was not natively meant for us to be building strategic market analysis or doing our digital marketing area assessments and planning there, right?
So that raw healthcare data needs to be interpreted and formed into a cleaner data model that's related more to the patient events, episodes of care, those types of things. So you have a data model and the associated constructed datasets.
And then traditionally, on top of this middle layer, you would stack BI and other query tools, right? These are these dashboards that we're all very familiar with. But dashboards have some inherent built-in limitations, right? Unless the dashboard has been built specifically to answer the question that you're asking at the moment, it may not be super useful, right? So there are definitely use cases—operational use cases—where you're looking at KPIs that you're trying to monitor. So BI and dashboards are never going to go away.
But what AI is promising, in my opinion, and our opinion here at Kythera, is a complementary user experience where I have a one-off question, or I get a question from the CEO. No, we have not built a dashboard specifically to answer that question, but I still need it answered, right? And so I have my analytics team, but they've got a bandwidth problem because everybody's hitting them for everything, right?
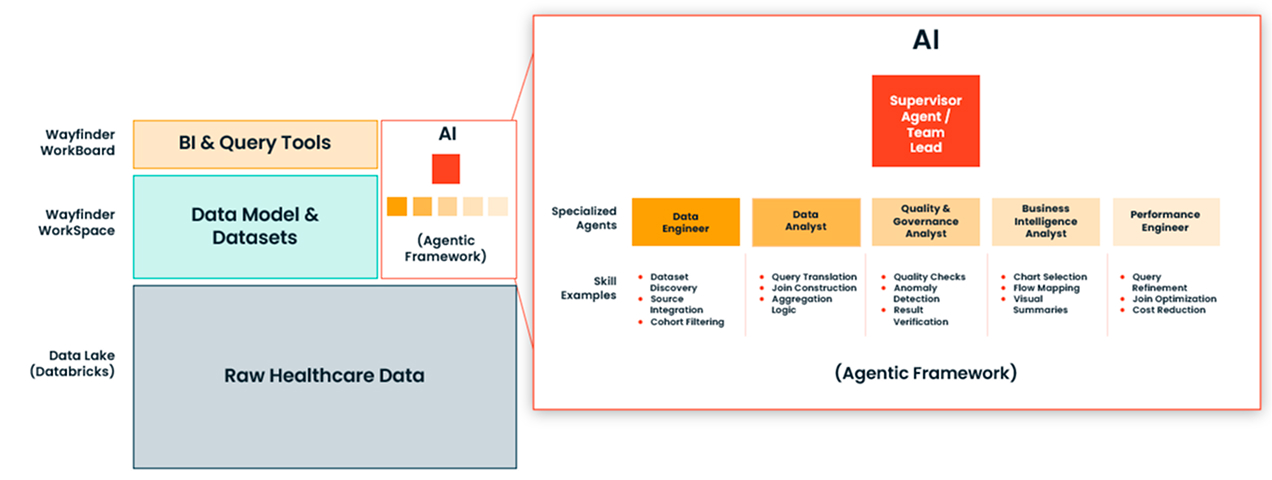
So, the promise here is that we have some AI agents that we can put alongside our current analyst team to help increase the bandwidth that they have and the access to the underlying data infrastructure that has probably been built in your organization so painstakingly, right? And so what this looks like in the end is actually it's not one AI agent. The best way to do this for data analysis is typically to have a team of agents that are organized in a very particular way.
\---
### Kythera's Multi-Agent Architecture
**Ryan Lerch:** This is a generic diagram, but what I want to demonstrate for you guys here real quick is a very specific real-life example, and it looks like this. This is a demo of Kythera's patient events dataset, and particularly we're looking at surgeries today. But the data exists for encounters of all types. And this is an example of that data that's been formatted—it's no longer claims in the EHR; it's been formatted to read very cleanly at an event level so that you can look at referrals and market share and other healthcare events that are happening in markets. This is a national dataset, just under 300 million patients over the last eight years, and again, remastered into an event-based representation, right?
So this specific team that we're going to be working with today has an AI team lead. This is the one that we're going to be interacting directly with through a chat interface. We're going to ask it questions, and this is the agent that's going to plan the analysis, and it's going to route specific data and other analytics requests to the other members of its analysis team.
On its team, we have four other agents:
1. **Practitioner Directory Analyst:** This is an expert in using Kythera's practitioner directory that has affiliations data, specialty data, and things like that.
2. **Facility Directory Analyst:** This is an agent that is an expert at all things facility directory—where things are located, what they are called, and what their system affiliation is.
3. **Patient Events Dataset Expert:** This is the agent that is the expert in using the patient events dataset that I've described. It knows all the ins and outs of working with that data and how to get those queries out.
4. **Coverage Advisor:** This is actually a major area of challenge when working with large third-party healthcare datasets—understanding what is and is not in the data natively. So, this gives us context to the sufficiency of the underlying data to support the requested analyses.
\---
### Live Examples \& Use Cases
#### Use Case 1: Market Share Analysis
**Ryan Lerch:** From here, we're going to go straight into just a quick example. I want to show you guys the practitioner directory analyst just so you can get a sense for what any individual agent is and how those kind of work.
This is a recording (just so that we can be timely here) of me asking the practitioner specialist, *"Show me info for surgeon Paul Thomas."* Well, the main challenge that's being addressed here is that there might be 20 Paul Thomases in the data, or there might not be anybody with the exact name Paul Thomas. So there's a matching problem that has to happen. The user question has to be turned into specific things that can be searched in the data.
So we can see here—let me stop it, it's getting a little ahead of me—the practitioner agent says, *"Okay, you asked for Paul Thomas. I found one, the surgeon, practicing in Tennessee."* Fantastic. So this gives me a chance to confirm that this is the doctor I was talking about. And so now the practitioner agent would return that information to our team lead agent and say, *"He said Paul Thomas, this is what he means. It's NPI 17200,"* et cetera.
So, that's a practitioner directory analyst. I'm checking my time here, so I'm going to move quickly into our first primary use case here, which is a common question in strategy: *"What is the market share of systems in my market?"*
This is a deceptively simple-sounding question, as I'm sure many of you guys know. First of all, you have to be able to see your own internal data. You have to be able to see external data about the market. You have to account for what's missing. So this sounds simple, but is not trivial.
So I'm going to start by asking our AI team lead, *"Let's do a market share analysis for Emory Health hospitals in Atlanta and their competitors."* Didn't plan it this way, but we have some of our friends from Atlanta on the call here today, so this is a little bit fortuitous for you guys.
The agent says, *"I'll help you with that. Let's do Emory Health. But let's start by resolving the facilities in the Atlanta market."* So you can see here that the very first step is that it makes a call to that facility directory specialist and says, *"Hey, show me Emory Health system and the hospitals in the Atlanta area."* Now it wants to find the competing hospital systems just to get the lay of the land.
I'm going to skip ahead a bit here because it's going to ask that facility directory questions in a series of ways. But then once it gathers all the information that it needs, it says, *"Okay, I have a good understanding of the facilities."* And here they are: we have Emory Healthcare hospitals in Atlanta Metro, and we have the major competitor health systems—Piedmont, WellStar, Grady, and Northside.
So then it poses a series of questions back to us: *"Now that we know the market you're talking about specifically... would you like me to focus only on the core Atlanta metro, or are there specific time periods? Are you interested in overall surgical volume, market share, or specific service lines?"* Our original question was very vague, and it's coming back to us saying, *"Hey, to answer your question, I need a little bit more detail."*
So I said, *"Let's just focus on core Atlanta Metro, the last two years, orthopedic service line."* Perfect. Now it's going to go and query our events analyst agent, asking, *"Show me the total count of surgical events for orthopedic."* It's just gathering more data from its teammates, and that's what makes this an agentic system.
I'm going to skip ahead here a little bit; there are multiple steps where it's asking for different cuts of the data so that it can assemble the final report. This process does take about 7 to 10 minutes, depending on the complexity and the market, which is why we prerecorded it. It's a little bit awkward to do it live in a demo, but 7 to 10 minutes to have a full market share report is actually pretty good, in my opinion.
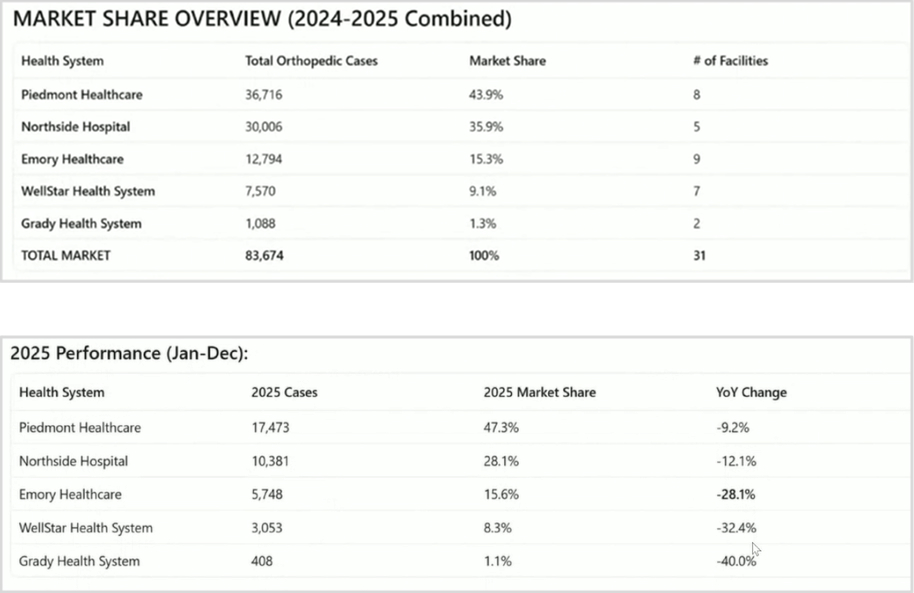
But here we go: there's the executive summary. We've got market share for that service line, with Piedmont leading strongly in the specific geography that was carved out here. We see the year-over-year trends. There's going to be some troubling data points in here that I want to point out. Let's pause it right here and look at this: minus 28.1%. Why is the volume dropping so significantly?
Our coverage agent has chimed in here and says, *"Note that significant volume drops starting in July 2025 are due to Medicare data lag."* So in the underlying claims data, the last data load for Medicare was July 2025, which explains this dramatic decline in the second half. Actual market shares through June are more representative of true competitive position. So it's going to represent those numbers correctly.
That was the system level. Now we come down to the facility level to get some benchmarking against this stuff. This is a fully featured report. One of the big advantages of working with a foundation model is that it has a lot of general knowledge, so it's able to understand how that data you've just presented from your internal system might compare and be actionable in the real world. Let's skip to growth opportunities: expand St. Joseph's, strengthen Johns Creek, and do physician recruitment. There are also notes about service lines and driving referrals.
#### Use Case 2: Referral Opportunities
**Ryan Lerch:** In the interest of time, I'm going to jump to our last use case here and continue following that lead. *(I accidentally stopped sharing. Apologies. Let me come back in and do that again.)*
The last question that we're going to ask for today is: *"What opportunities do I have to increase my referrals to my system?"* I'm trying to drive some additional volume and increase that market share.
Turning back to our same team and the same team lead agent, I say: *"All right, now show me physicians that don't refer more than 70% of their orthopedic patients to any one orthopedic surgery practice."* What I'm getting at here is I want to find folks that are "splitters"—they're not overly loyal or affiliated with my competitors. And you'll see that the agent interprets that on its own as we go here.
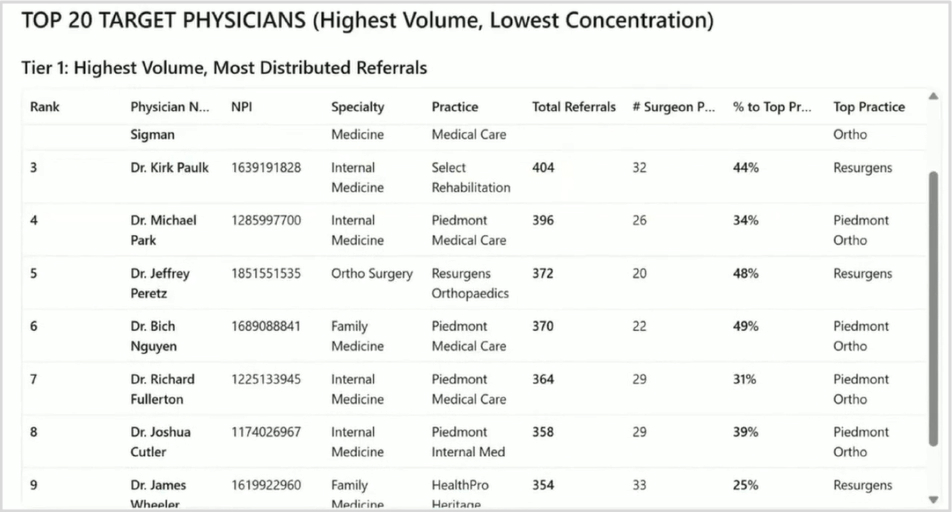
It's going to do a similar thing: make a bunch of calls to our events analyst, and then assemble a final report. Here's our executive summary: it identified 177 referring physicians in the Atlanta area who have at least 100 ortho patients, send less than 70% of their referrals to any single ortho surgeon or practice, and demonstrate distributed referral patterns across multiple surgery groups.
It shows the top 20 physicians with the highest volume and lowest concentration. These are specific individuals. Great.
Then it provides key insights on top targets. A few are specifically called out, like Dr. Carolyn Sigmond, who has the second-highest volume and currently sends 52% to Piedmont, but despite her Piedmont affiliation, refers broadly. So maybe there's some opportunity there for Emory.
Then there is Tier Two, which consists of high-volume primary care physicians. They don't have as many referrals directly to ortho, but they are still large referral sources ultimately (family medicine physicians). The report maps out the geographic distribution of those target physicians, their key locations, and definitions about how the distribution breaks up within the market.
I'm going to skip through the rest of this, but it provides strategic recommendations for immediate outreach. For a few folks, it just says, *"Hey, these are your high-value targets,"* and offers a value proposition: highlight Emory's academic excellence, emphasize shorter wait times, offer white-glove service, and create direct access lines to Emory orthopedic surgeons, et cetera.
The key point here is that it's pulling from our own actual internal and third-party data to generate real numbers that you might not be able to get easily in other ways. Because of time, I am going to end it there and switch back over.
\---
### Q\&A Session
**Caitlin Ryan:** So interesting and really helps set the context around what you can do with AI when you have a strong data and infrastructure foundation. We did have a few questions come in through the chat. I don't know if we'll have time for all of them, but we'll try to get to what we can. Again, if we don't answer your question, we'll follow up with you after.
**Question 1:** *How is this different from using ChatGPT or Claude against our own data?*
**Ryan Lerch:** Okay. Yeah. Well, ChatGPT and Claude definitely have viable use cases, and you're probably using them today in many ways. But one of the things that you can't do on standard implementations of ChatGPT is ask it about something that's in one of your own internal data systems because it's got no connection in.
Now, there are ways of using things like Claude Code or tools on a local system where you could potentially get access into that data, but there are a few gotchas. When using those models, you're still wired to Anthropic's or OpenAI's hosted foundation models. So when you're querying your internal datasets, if your architecture is not appropriately set up, you may be accidentally round-tripping patient data through Anthropic or OpenAI servers. So that's one of those where you can say, *"Yes, it's kind of possible,"* but it is really going to miss the mark from a security and governance standpoint.
**Caitlin Ryan:** All right. And then someone else asked:
**Question 2:** *How much effort does it typically take to get from a proof of concept to something that's production ready?*
**Ryan Lerch:** Oh, I could interpret that in several ways, and maybe this is a good one for a specific follow-up with the person who asked. But if you mean globally—how long would it take to start something like this from scratch—first, you have to account for the data layer. That could take several years if you haven't started one of those types of projects already or if you don't have a big team in place already working on making good use of your internal data and patching in external third-party data.
We work with companies all the time where, with our platform and the solutions we've figured out, we can get this installed in your organization with the first steps of installation typically within a few weeks, and have it fully up and running in several months at the most. So, yeah, we'll follow up with the asker to get a little bit more detail there.
**Caitlin Ryan:** Okay. And then the last one that we'll have time for today is:
**Question 3:** *Can your AI produce inaccurate or hallucinated results, and how do you mitigate against that risk?*
**Ryan Lerch:** Oh, that's a good one. Yeah, absolutely. This is a characteristic of this technology in general across all of its applications. We've seen that if you ask it to write an email for you, it'll sometimes come up with some off-the-wall things.
But there are definitely major advancements that have been made in the space around tuning and monitoring these different agents. This is actually the reason why—though we didn't go too deep into it during the talk—we design a supervisor agent alongside separate agents on a team. It allows these agents to be highly specialized in a very small thing.
Going back to our example, we have an agent that only knows how to use the practitioner directory. We can do an awful lot to make sure that it really knows exactly what it's doing, what it's supposed to do, and doesn't make any mistakes. There are testing and monitoring frameworks where you can continually inject questions and compare the answers it's getting to make sure that it's behaving well over time. The general answer to minimizing that type of error is to specialize and keep the context very narrow for any one agent.
\---
### Conclusion
**Caitlin Ryan:** Great. Well, thank you. I think that's all we have time for today. I just want to thank everybody who's joined us, and Ryan, thank you for your time.
**Ryan Lerch:** Thank you.
**Caitlin Ryan:** If you'd like to learn more about Kythera, you can find us on LinkedIn. You can find Ryan there as well. Or you can visit us at kytheralabs.com.

©2026 Kythera Labs, Inc. All rights reserved.
