Before the recent explosion of Large Language Model (LLM) technology, other technologies under the “AI” umbrella have long been used in healthcare for a growing number of use cases, from imaging diagnostics to operations to drug discovery. Generative AI (Gen AI) and LLMs, in particular, are poised to further this trend into previously unaddressable use cases.
Terminology
Generative AI is a distinct type of artificial intelligence that can create new content by learning patterns and structures from large datasets. Unlike traditional AI systems designed for specific tasks or applications, generative AI models can create new content by learning patterns and structures from large datasets.
Large Language Model refers to a type of artificial intelligence model, particularly in the field of natural language processing (NLP), that is trained on vast amounts of text data to understand and generate human-like text. These models are characterized by their size, complexity, and ability to process and generate text in multiple languages.
LLMs are perfectly suited for generating impressive and often even amazing natural language outputs as a response to natural language prompts. Most of us have already used tools, like ChatGPT or Gmail Smart Compose, for basic research or to help create content. We think of these types of AI applications as highly trained assistants that we can utilize without the need for sophisticated training or special technology architecture. As long as one follows basic guidelines for not submitting sensitive data as part of their prompts, these hosted AI platforms can be used immediately to dramatic effect.
There is however a bigger, potentially more game-changing application: Gen AI to query one’s own internal data and provide actionable insights to questions of strategy, business development, and market intelligence. Healthcare providers have already been using data and analytics to support strategy and business intelligence, and LLMs can dramatically enhance their ability to discover answers from the data. LLMs are particularly adept at learning patterns in language from large corpuses of documents. Recent advancements have shown impressive results in generating analytical queries (coding languages are languages, too!) given prompts in natural language. This could enable non-coders to unlock insights from the data repositories that often exist in large organizations but are often only accessible to business users with skills like data science and analytics. While the lure of using fast-acting hosted AI platforms, like Chat GPT and others, may be strong, it is important to recognize that they run on 3rd party architectures, requiring data (or sensitive metadata) to be supplied as part of a prompt, leaving an organization’s infrastructure to be processed. The terms and conditions of these sites often allow these third parties to use all the data supplied in further training and tuning of their models, therefore making it difficult to maintain the security of sensitive data. Establishing a native capability within an organization to host LLMs privately can eliminate this risk.
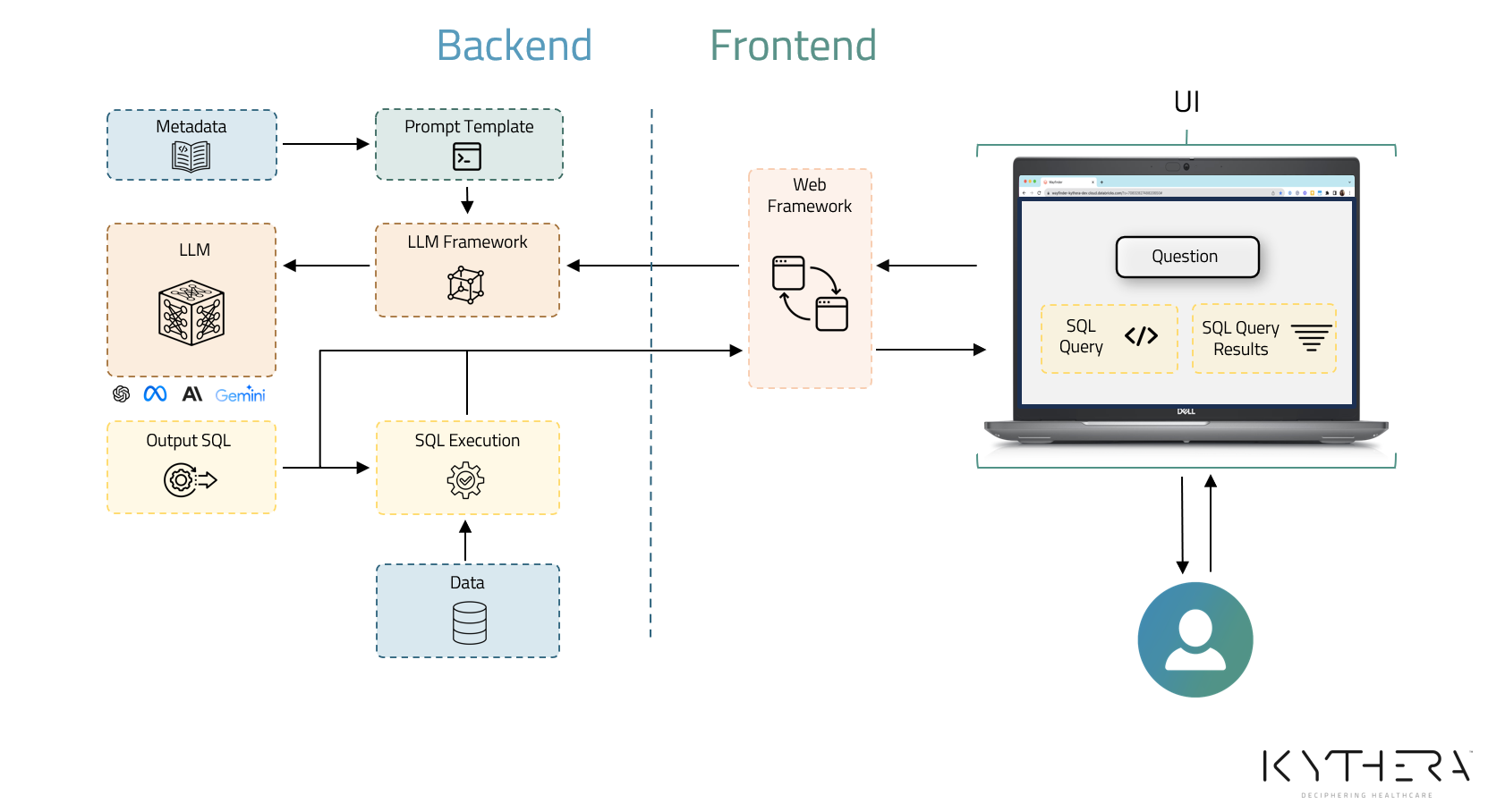
Kythera Labs is building LLM-powered utilities for querying healthcare data sets to improve our internal operations and enable our provider customers to realize better and more rapid ROI using our existing high-quality common data model and patient event data sets. Here’s how we got started.
How Kythera Got Started
Rather than build our own, Kythera partnered with Databricks, leveraging their Data Intelligence Platform. The Platform provides the basic architecture for hosting and tuning LLMs within an organization’s own architecture out of the box. Having an appropriate architecture is just the first step, however. Ensuring the accuracy and interpretability of the generated results requires a tremendous amount of focus on data quality and ensuring that the data model is fit for purpose. Kythera’s history of turning petabytes of raw healthcare data into high-fidelity, use-case-ready analytics provided an ideal starting point.
To produce “answer-ready” analytics, we developed a dynamic common data model that restructures and reformats, removes incorrect information, imputes correct information, and infers the existence of missing healthcare events. The model enables us to bring together data from different sources and simplifies and organizes the data. The model works like a feedback loop that self-informs and improves the data by interacting with thousands of data points.
Data Quality
Why the intense focus on data quality? High-quality data is the foundation for LLM success. Everyone who works with data is familiar with the phrase “garbage in-garbage out,” and this is especially true with LLMs. With poor-quality data as an input, the model might produce an impressive, perfectly written query that results in an impressively wrong answer. Not only does the data need to be of the highest quality, it also needs to be fit-for-purpose.
Fit-For-Purpose
Fit-for-purpose data is essential for driving informed decision-making, enabling evidence-based insights, and achieving desired outcomes. For LLMs, that means using data that is suitable, relevant, and appropriate. A challenge faced when developing LLMs for writing data analytics queries is that they are not yet good enough for complex reasoning or solving problems that require multi-step logic to produce a correct answer. We have found that the closer the elements represented in the data match the concepts relevant to the query, the better the models are able to perform in generating queries that produce accurate results. For example, if the analyst’s questions are related to:
- erosion of surgical volumes from inpatient to outpatient facilities
- referral alignment among physician practices
- common treatment patterns for patients with chronic disease
Data specifically structured with these elements present and resolved (extensive pre-processing is often required here - especially with claims data) performs far better than attempting to answer complex questions like these on raw source data like claims data. We have developed a longitudinal patient event data asset that is curated and optimized and is a perfect starting point to train our models.
If you are considering getting into AI, really understand the data you are using or have access to. First, ask yourself if you can evaluate the effectiveness and quality of the data that you will be using in your model. Also consider if the data is “fit-for-purpose.” A fit-for-purpose data set to train the model will help ensure better model success.
Pick The Right Use Case
The use cases for LLMs and Gen AI are expanding, so it is imperative to keep a few key things in mind. Rather than starting with a model or specific technology, it is advisable to begin by identifying a specific problem you are trying to solve with a specific use case. In keeping the use case narrow, you can measure the model effectiveness and then understand if the model is scalable. Gen AI aids your decision-making by analyzing huge data sets; however, it still requires human expertise, intervention, and supervision. If you start too large, you may end up with questionable outputs and not really know how the model produced them.
As Kythera began developing and tuning our model, we used a small number of use cases typical of healthcare strategy and market growth professionals. As we monitored the models performance, we began to fine-tune and call out best practices. Our prompt engineering grew more refined based on the outputs we were seeing. Transparency about the data used, the code used to generate the answers, and how the model functions is critical for gaining acceptance and having confidence in the outputs. As we fine-tuned, we cataloged instruction sets for each use case to reduce the time to insights.
Conclusion
The Gen AI landscape is rapidly evolving and there are several things that you should consider right now.
- Do you have a platform that can help you do the heavy lifting, one that can handle large amounts of data required for modeling and optimized for AI?
- Do you have high-quality, fit-for-purpose data for your model input?
- Do you have appropriate governance policies and tools to ensure you have access to your data and models and that they cannot be shared without your permission?
- Have you defined an initial narrow and specific use case?
- Do you have a culture of transparency about the data used, the code used to generate the answers, and how the model functions?
- Have you enlisted subject matter experts who can assess and validate the model outputs?
- Do you have a partner that can help you get started?
The benefits of faster time to insights and more efficient use of resources for technical and non-technical staff can be achieved through the application of Generative AI for analytics. While this field is emerging, we hope you found this post informative about our process and would be happy to share our experience and insights with you. Get in touch or connect with me on LinkedIn.